miércoles, 12 de diciembre de 2012
domingo, 9 de diciembre de 2012
EJEMPLO DE JOINS MySQL
En esta practica aplicamos los 7 tipos de JOIN's permitidos por MySQL, a continuación se muestra el scritp.
drop database if exists jointipos;
create database jointipos;
use jointipos;
create table funciones(
id_funcion varchar(4) not null,
nom_funcion varchar(7)not null,
primary key(id_funcion)
)type=innodb;
insert into funciones values('A-01','Mecanico');
insert into funciones values('A-02','Carpintero');
insert into funciones values('A-03','Bombero');
create table deptos(
id_depto varchar(4) not null,
nom_deptp varchar(7)not null,
primary key(id_depto)
)type=innodb;
insert into deptos values('B-01','Taller 1');
insert into deptos values('B-02','Taller 1');
insert into deptos values('B-03','Estación');
create table localidad(
id_localidad varchar(4) not null,
nombre varchar(15)not null,
primary key(id_localidad)
)type=innodb;
insert into localidad values('C-01','Benito Juarez');
insert into localidad values('C-02','Lindavista');
insert into localidad values('C-03','Coapa');
create table empleado(
id_empleado varchar(7) not null,
nom_empleado varchar(10) not null,
id_funcion varchar(4) not null,
id_depto varchar(4) not null,
id_localidad varchar (4) not null,
primary key(id_empleado),
foreign key (id_funcion) references funciones(id_funcion) on update cascade,
foreign key (id_depto) references deptos(id_depto) on update cascade,
foreign key (id_localidad) references localidad(id_localidad) on update cascade
)type=innodb;
insert into empleado values('01','JUAN','A-02','B-02','C-01');
insert into empleado values('02','CARLOS','A-03','B-03','C-02');
insert into empleado values('03','ARTURO','A-01','B-01','C-03');
insert into empleado values('04','DIEGO','A-03','B-03','C-01');
insert into empleado values('05','LUIS','A-01','B-01','C-02');

Aplicando el "LEFT JOIN" :
select * from table1,table2 where table1.id=table2.id;


Aplicando el "INNER JOIN"
select from empleado.id_empleado,deptos.id_depto,empleado.nom_empleado from empleado inner join deptos on empleado.id_empleado=deptos.id_depto;


Aplicando el "RIGHT JOIN"
select empleado.id_empleado,deptos.id_depto,empleado.nom_empleado from empleado right join deptos on empleado.id_empleado=deptos.id_depto;

Aplicando un "OUTER JOIN"
select empleado.id_empleado,deptos.id_depto,empleado.nom_empleado from empleado right OUTER join deptos on empleado.id_empleado=deptos.id_depto;


APLICANDO EL EQUI JOIN
select * from empleado inner join deptos on empleado.id_depto=deptos.id_depto;


APLICANDO EL NATUAL JOIN
select * from empleado naturla join deptos;


APLICANDO EL CROSS JOIN
selec * from empleado cross join funciones:


lunes, 3 de diciembre de 2012
domingo, 11 de noviembre de 2012
Concepto de base de datos
Una base de
datos es el conjunto de datos informativos organizados en un mismo contexto
para su uso y vinculación.
Se le llama
base de datos a los bancos de información que contienen datos relativos a
diversas temáticas y categorizados de distinta manera, pero que comparten entre
sí algún tipo de vínculo o relación que busca ordenarlos y clasificarlos en
conjunto.
Una base de
datos es un almacén que nos permite guardar grandes cantidades de información
de forma organizada para que luego podamos encontrarla y utilizarla fácilmente.
Una base de
datos es una recopilación de información relativa a un asunto o propósito
particular, como el seguimiento de pedidos de clientes o el mantenimiento de
una colección de música.
Elementos de la base de datos
Tabla
Se refiere al
tipo de modelado de datos, donde se guardan los datos recogidos por un
programa. Su estructura general se asemeja a la vista general de un programa de
hoja de cálculo. Se compone por campo y registro.

Campo
Es la unidad
básica de una BD, los nombres de los campos no pueden empezar con espacios en
blanco y caracteres especiales, no pueden llevar puntos, ni signos de
exclamación o corchetes. La descripción de un campo permite aclarar información
referida a los nombres del campo.

Registro
Cada fila de
una tabla representa un conjunto de datos relacionados, y todas las filas de la
misma tabla tienen la misma estructura.

Tipos de base de datos
Hay diversos
tipos de base de datos dependiendo de los objetivos de uso. Por ejemplo, son
distintos objetivos mantener el historial de los pacientes de un hospital o el
registro de operaciones financieras de un banco.
·
Relacionales
Éste es el
modelo utilizado en la actualidad para modelar problemas reales y administrar
datos dinámicamente. Tras ser postulados sus fundamentos en 1970, de los
laboratorios IBM en San José, no tardó en consolidarse como un nuevo paradigma
en los modelos de base de datos. Su idea fundamental es el uso de
"relaciones". Estas relaciones podrían considerarse en forma lógica
como conjuntos de datos llamados "tuplas". Pese a que ésta es la
teoría de las bases de datos relacionales creadas por Codd, la mayoría de las
veces se conceptualiza de una manera más fácil de imaginar. Esto es pensando en
cada relación como si fuese una tabla que está compuesta por registros (las
filas de una tabla), que representarían las tuplas, y campos (las columnas de
una tabla).
En este
modelo, el lugar y la forma en que se almacenen los datos no tienen relevancia
(a diferencia de otros modelos como el jerárquico y el de red). Esto tiene la
considerable ventaja de que es más fácil de entender y de utilizar para un
usuario esporádico de la base de datos. La información puede ser recuperada o
almacenada mediante "consultas" que ofrecen una amplia flexibilidad y
poder para administrar la información.
El lenguaje
más habitual para construir las consultas a bases de datos relacionales es SQL,
Structured Query Language o Lenguaje Estructurado de Consultas, un estándar
implementado por los principales motores o sistemas de gestión de bases de
datos relacionales.
Durante su
diseño, una base de datos relacional pasa por un proceso al que se le conoce
como normalización de una base de datos
· Jerárquicas
Éstas son
bases de datos que, como su nombre indica, almacenan su información en una
estructura jerárquica. En este modelo los datos se organizan en una forma
similar a un árbol (visto al revés), en donde un nodo padre de información
puede tener varios hijos. El nodo que no tiene padres es llamado raíz, y a los
nodos que no tienen hijos se los conoce como hojas.
Las bases de
datos jerárquicas son especialmente útiles en el caso de aplicaciones que
manejan un gran volumen de información y datos muy compartidos permitiendo
crear estructuras estables y de gran rendimiento.
Una de las
principales limitaciones de este modelo es su incapacidad de representar
eficientemente la redundancia de datos.
Red
Éste es un
modelo ligeramente distinto del jerárquico; su diferencia fundamental es la
modificación del concepto de nodo: se permite que un mismo nodo tenga varios
padres (posibilidad no permitida en el modelo jerárquico).
Fue una gran
mejora con respecto al modelo jerárquico, ya que ofrecía una solución eficiente
al problema de redundancia de datos; pero, aun así, la dificultad que significa
administrar la información en una base de datos de red ha significado que sea
un modelo utilizado en su mayoría por programadores más que por usuarios
finales.
· Distribuidas
Una base de
datos distribuida es, una base de datos construida sobre una red computacional
y no por el contrario en una maquina aislada. La información que constituye la
base de datos esta almacenada en diferentes sitios en la red, y as aplicaciones
que se ejecutan accesan datos en distintos sitios.
Una bases de
datos distribuida entonces es una colección de datos que permanece
lógicamente a un solo sistema, pero se
encuentran físicamente esparcido en varios sitios de la red. Un sistema d base
de satos distribuidas se compone de un conjunto de sitios, conectados entre si
mediante algún tipo de red de comunicaciones, en el cual:
· Cada sitio es un sistema de base de
datos de si mismo.
· Los sitios han convenido en trabajar
juntos (si es necesario) con el fin de que un usuario de cualquier sitio pueda
obtener acceso a los datos de cualquier punto de la red tal como si todos los
datos estuvieran almacenados en el sitio propio del usuario.
En
consecuencia la llamada BDD es en realidad una especie de objeto virtual, cuyas
partes componentes se almacenan físicamente en varias bases de datos reales
distintas ubicadas en diferentes sitios. De hecho, es la unión lógica de esas
bases de datos. En otras palabras, cada sitio tiene sus propias bases de datos
reales locales, sus propios usuarios locales, sus propios DBMS y programas para
la administración de transacciones, y su propio administrador local de
comunicación de datos. En particular un usuario puede realizar operaciones
sobre los datos en su propio sitio local exactamente como si ese sitio no
participara en absoluto en el sistema distribuido. Así pues, el sistema de BDD
puede considerarse como una especie de sociedad entre los DBMS individuales
locales de todos los sitios.
15 tipos de datos
Alfanuméricos.
Se utilizan para almacenar textos que pueden contener letras y números, pero
teniendo en cuenta que los números serán tratados como un carácter más.

Numéricos,
enteros. Se utilizan para almacenar valores numéricos sobre los que, al
contrario que en los tipos alfanuméricos, se podrán realizar operaciones aritméticas.
En las propiedades de los reales hay que indicar cuántas de las cifras del
tamaño asignado serán decimales (se conoce también como la escala).


Temporales.
Se utilizan para guardar fechas y/o horas.

Especiales.
Tipos de datos que no entran en ninguna de las clasificaciones anteriores.

LDD y LMD
Un SGBD ofrece fundamental mente dos tipos de lenguaje, uno para la
definición y otro para la manipulación.
Lenguaje de Definición de Datos (LDD).- Nos va a permitir definir la
estructura de la BD mediante la definición de los tipos de datos que la
componen y las restricciones de esos datos, asi como
sus características de tipo físico (Volumenes,Longitud de campo,...),
y las vistas lógicas de los usuarios (nombre, datos, y la
interrelación que la componen).
Lenguaje de Manipulación de Datos.- Facilita a los usuarios el acceso y
manejo de los datos, encargándose de las tareas de actualización,
borrado y consulta. Estos lenguajes pueden ser precedurales (aquellos que
requieren que datos se necesitan y como obtenerlos) y no procedurales
(requieren que datos necesitan pero sin indicar como obtenerlos).
Uno de los lenguajes mas utilizados en las BDR es el SQL (Structured
Query Language). Se ha adoptado como un lenguaje de alto
nivel estándar de comunicaión con BD. Se trata de una
combinación de LDD y LMD, así como sentencias que permiten tener el
control sobre el acceso a los datos de la base y de las operaciones sobre ella
y que constituyen el "lenguaje de control de datos".
El LDD ésta formado por un grupo de sentencias que permiten la
definición y declaración de los objetos que componen la BD. Estos objetos
pueden ser la propia BD (DataBase), las tablas (TABLE), las vistas (VIEW), los
indices (INDEX), los procedimientos almacenados (PROCEDURE), los disipadores
(TRIGGER), las reglas (RULE), los dominios (DOMAIN), y los valores por defecto
(DEFAULT). Los comados que se utilizan para definir estos objetos son CREATE (creación),
DROP (eliminación) y ALTER (modificación).
El LMD esta formado por sentencias que permten manejar los datos
almacenados a nivel de filas o columnas. Estas
sentencias están formadas por una localización y la acción sobre
ella. Estas acciones pueden ser de recuperación o de actualización.
Los comandos utilizados en las acciones de actualización son INSERT
(inserción), UPDATE (actualización) y DELETE (borrado), y en las acciones de
recuperación el comando SELECT (consulta de datos que cumplan un requisito
determinado).
OPERACIONES (OPERADORES) DE MYSQL.
OPERADORES.
Los operadores son los bloques con los que se construyen las consultas
complejas. Los operadors logicos AND y OR, permiten asociar varias condiciones
de distintas formas. Los operadores aritméticos como + o *, permiten
realizar operaciones matemáticas basicas en sus consultas. Los
operadores de comparación como < o >, permiten comparar valores y
restringir los conjuntos de resultados. Por ultimo. los operadores bit a bit,
aunque no se utilicen habitualmente, permiten trabajar con bits en las
consultas.
OPERADORES LÓGICOS
Los operadores lógicos reducen las opciones a true (1) o
false (0). Por ejemplo, si le pregunto si es hombre OR mujer (estoy asumiendo
que quiero una respuesta afirmativa o negativa), la respuesta sera si o true.
Si la pregunta fuera si es hombre AND mujer, la respuesta seria no, o false.
Los operadores AND y OR utilizados en las preguntas son
operadores lógicos. En la siguiente tabla (3.1) se describen los operadores
de forma mas detallada.

OPERADORES ARITMÉTICOS.
Los operadores aritméticos se usan para realizar
operaciones aritméticas elementales. Por ejemplo en la
expresión 2 + 3 = 5, el signo más (+), es un operador
aritmético. En la siguiente tabla (3.2) se describen los operadores
aritméticos los operadores aritméticos permitidos por mysql.


OPERADORES DE COMPARACIÓN.
Los operadores de comparacion se utilizan para realizar comparaciones
entre valorcs. Por ejemplo, podemos afirmar que 34 cs mayor que 2. La
espresion es mayor que es un operador de comparación. La tabla 3.3 lista y
describe los operadores de comparación utilizados en MvSQL.

OPERADORES BIT A BIT
Para entender como funcionan las operaciones bit a bit, es necesario
conocer un poco los números booleanos y la aritmetica booleana. Este
tipo de consulta no se suele utilizar, pero cualquier experto en ciernes
que se precie necesitara incluirlas en su repertorio. En la tabla 3.6 se
describen 10s operadores bit a bit.

CONSULTA, PROYECCION, PRODUCTO NATURAL Y PRODUCTO CARTESIANO.
PROYECCIÓN

Para
obtener una relación que tenga sólo los atributos nombre y apellido de los
empleados de administración, podemos hacer una proyección en la
relaciónEMPLEADOS_ADM sobre estos dos atributos. Se indicaría de la forma
siguiente: EMPLEADOS_ADM [nombre, apellido].
A
continuación definiremos los atributos y la extensión de la relación resultante
de una proyección

Ejemplo de
proyección
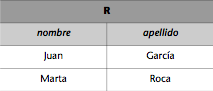
Si queremos
obtener una relación R con el nombre y el apellido de todos los empleados de
administración de la base de datos del ejemplo, haremos la siguiente
proyección:
R := EMPLEADOS_ADM[nombre, apellido].
Entonces, la
relación R resultante será:
CONSULTAS
CONEXIÓN A LA BASE DE DATOS
Para conectarnos a la base de datos en primer lugar debemos conocer el
nombre de nuestra base de datos, nombre de usuario y contraseña. Esto lo
podemos conocer directamente desde el phpMyAdmin que nos proporcionan la
mayoria de los servidores. En el ejemplo que van a ver a continuación creamos
una variable la cual contiene la función mysql_connect(); esta nos indica de
que hemos realizado una sesión dentro del MySQL, devolvera "false" en
caso de no conseguirse dicha sesión, y "true" en caso de conseguirse,
para realizar dicha conexión debemos especificar nuestro nombre de usuario y
contraseña, esta sesión nos hara poder acceder a seleccionar la base de datos
que queremos, dicha sesión durara hasta que usemos mysql_close(); para cerrar
la sesión dentro del MySQL.
La función mysql_select_db(); devuelve el valor "false" en
caso de no conectarse a dicha base de datos, claro esto ocurrira en caso de no
exisitir la base de datos ó en caso de colocar nombre de usuario y contraseña
falsos, y devuelve "true" en caso de lograr dicha conexión a la base
de datos, luego procedemos a colocar la variable $con para indicar nuestra
sesión en la base de datos. MySQL es "case-sensitive", esto quiere
decir que diferencia base de datos que tenga nombre en letras mayúsculas y
minusculas, si le colocamos a una base de datos el nombre de 'Usuarios', para
llamarla no va ser lo mismo si colocamos como nombre 'usuarios' ya que buscara
una base de datos que contenga el nombre de 'usuarios' y no 'Usuarios', por eso
se recomienda mantener un standard a la hora de elegir los nombres de las
distintas base de datos.
<?php
$con =
mysql_connect('localhost','usuario','contraseña'); // Conexión a la MySQL.
mysql_select_db('base_de_datos',$con); // Elegimos nuestra base de
datos, registramos nuestra conexión a la MySQL.
?>
CONSULTAS A LA BASE DE DATOS
Una vez logrado la conexión a la base de datos, podemos realizar
nuestras consultas a dicha base. Si todavía no hemos creado una tabla en la
base de datos debemos crearla para poder realizar con exito dichas consultas.
La función para realizar dichas consultas se llama mysql_query(); esta función
esta constituida por el tipo de sentencia a realizar y indicar el identificador
de la conexión a la base de datos, en este caso $con. Los valores retornados
para las sentencias SELECT, SHOW, DESCRIBE o EXPLAIN, regresa un
"resource" en caso exitoso, y "false" en error. Para otro
tipo de sentencia SQL, UPDATE, DELETE, DROP, etc, regresa "true" en
caso exitoso y false en error. El resultado obtenido debe ser pasado a
mysql_fetch_array(); y otras funciones para el manejo de las tablas del
resultado, para accesar los datos regresados.
Los tipos de sentencia mas comunes son SELECT, UPDATE, DELETE, las
cuales a su vez estan constituidos por otras sentencias que nos pueden
modificar el tipo de consulta que queremos hacer. Nota: Antes de hacer los
querys tienes que incluir tu conexión a la base de datos, es decir, el
porcedimiento que anteriormente realizamos, lo puedes colocar en un archivo e
incluirlo mediante un include(); si es de tu preferencia, si esto no se hace no
podrás realizar dichos querys ya que no existe conexión a la MySQL.
<?php
// Variable que contiene
nuestra consulta
$query =
mysql_query("SELECT * FROM usuarios ORDER BY id DESC LIMIT 0,50",$con);
.
?>
PRODUCTO CARTESIANO
El producto
cartesiano es un tipo de composición de tablas, aplicando el producto
cartesiano a dos tablas se obtiene una tabla con las columnas de la primera
tabla unidas a las columnas de la segunda tabla, y las filas de la tabla
resultante son todas las posibles concatenaciones de filas de la primera tabla
con filas de la segunda tabla.
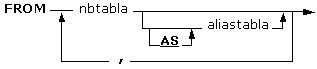
La sintaxis
es la siguiente:
El producto
cartesiano se indica poniendo en la FROM las tablas que queremos componer
separadas por comas, podemos obtener así el producto cartesiano de dos, tres, o
más tablas.
nbtabla puede ser un nombre de tabla o un
nombre de consulta. Si todas las tablas están en una base de datos externa,
añadiremos la cláusula IN basedatosexterna después de la última tabla. Pero
para mejorar el rendimiento y facilitar el uso, se recomienda utilizar una
tabla vinculada en lugar de la cláusula IN.
Hay que tener en cuenta que el producto
cartesiano obtiene todas las posibles combinaciones de filas por lo tanto si
tenemos dos tablas de 100 registros cada una, el resultado tendrá 100x100
filas, si el producto lo hacemos de estas dos tablas con una tercera de 20
filas, el resultado tendrá 200.000 filas (100x100x20) y estamos hablando de
tablas pequeñas. Se ve claramente que el producto cartesiano es una operación
costosa sobre todo si operamos con más de dos tablas o con tablas voluminosas.
Se puede componer una tabla consigo misma, en
este caso es obligatorio utilizar un nombre de alias por lo menos para una de
las dos.
Por ejemplo:
SELECT * FROM empleados, empleados emp
En este
ejemplo obtenemos el producto cartesiano de la tabla de empleados con ella
misma. Todas las posibles combinaciones de empleados con empleados.
FUENTE
Suscribirse a:
Comentarios (Atom)